

Brainy Sunday #4 - Alerte au tsunami et aux biais
Brainy Sunday #4 - Alerte au tsunami et aux biais
Grosse vague de nouvelles IA, Stéortypes et biais de genre dans les modèles et, bien sûr, des liens toujours aussi époustouflants.

C'est avec plaisir que je te présente cette quatrième édition de Brainy Sunday, ton rendez-vous hebdomadaire pour suivre les évolutions des IA et nourrir tes neurones.
Cette semaine, je fais un point rapide sur l'arrivée imminente de nouveaux modèles d'IA complètement dingues 🤯 puis on discutera de la question des biais de genre (mais pas que) dans les IA. On finira bien entendu par quelques bons liens et un résumé des dernières actualités.
Si tu as reçu ce mail d’un·e ami·e ou que tu l'as trouvé en ligne, n'oublie pas de t'inscrire pour recevoir les prochaines éditions !
🚨 Alerte Tsunami
Si cette semaine n’a pas été avare en nouveautés (pour changer…), elle annonce surtout un véritable raz-de-marée pour les prochains jours. Prépare-toi à un véritable Tsunami d’IA (oui, encore un) :
🌊 GPT-4 le nouveau modèle d’OpenAI arrive. On s’attend à une annonce le 16 Mars à l’occasion d’une nouvelle conférence de Microsoft. Le plus gros changement anticipé est qu’il sera multimodal et donc capable de comprendre ou générer des images ou des vidéos en plus du texte.
🌊 Midjourney V5 sera disponible très très bientôt. Les utilisateurs ont été invités à évaluer des images pré-générées par cette nouvelle version et constatent de nombreuses améliorations.
🌊 En matière de génération d’images, DALL-E 3 est également annoncé du côté d’OpenAI. Ici aussi, le modèle semble avoir fait de gros progrès.
🌊 Wonder Dynamics a teasé un nouvel outil qui anime, éclaire et compose automatiquement des personnages de synthèse dans une scène en direct (tu dois voir cette vidéo)
🌊 Rien d’officiel n’a réellement été annoncé, mais la fuite d’une version pirate de Llama, le modèle de langage de Meta, risque fort de provoquer la sortie d’app ou de site qui l’utilisent, par Meta ou quelqu’un d’autre.

🤔 Nos IA sont elles biaisées ?
Images et stéréotypes de genre
Mercredi dernier nous étions le 8 Mars et c’était donc la Journée internationale des droits des femmes. Une occasion pour l’association #JamaisSansElles d’attirer notre attention et de questionner la représentation des genres par les IA - particulièrement celles qui génèrent des images.
Cette campagne, qui fait écho à la campagne internationale Missjourney, dénonce la manière dont les métiers prestigieux sont quasi systématiquement représentés par des images d’hommes alors que des métiers moins prestigieux le sont par des femmes.
Ce type de biais n’est évidemment pas propre à l’IA. Mais ce qui est important ici, et c’est essentiellement ce que dénoncent ces campagnes, c’est qu’il y soit aussi présent. Et je pense qu’elles ont raison : il est important d’être conscient des biais qui peuvent exister dans les contenus générés par IA sinon on risque fort d’entretenir et propager les stéréotypes.
Des biais (re)connus dès le départ
A ce propos, il faut noter que les premiers à reconnaître et dire que les modèles d’IA sont biaisés sont leurs concepteurs eux-mêmes. La plupart des annonces de produits IA et des publications de recherches dans le domaine en font mention et signalent, au minimum, que le modèle reprend les biais présents dans les données qui ont servis à le concevoir.
Les chercheurs parlent plus souvent de biais d'algorithme que de biais d'intelligence artificielle mais cela revient au même : cela désigne la tendance des programmes et algorithmes à refléter les biais humains et donc à retourner des résultats biaisés, voir incorrects.
Ces biais sont dus à une erreur dans l’hypothèse du processus d’apprentissage automatique. Pour les IA, la cause la plus fréquente est la présence de biais dans les données d’entraînement elles-même. Et l’erreur la plus commune est sans doute de considérer ces données comme “neutres” ou même “représentatives de la réalité”.
Reprenons l’exemple des portraits de CEO : aujourd’hui 26% des CEO sont des femmes. Nous ne savons pas quel pourcentage des images de CEO utilisées pour entraîner Midjourney étaient des hommes - mais il n’y a certainement pas un 1/4 des images de CEO qu’il génére qui représentent des femmes. La boucle est bouclée: l’IA répercute les préjugés présents dans ses données, parfois même en les amplifiant.
Cela ne concerne pas que la génération d’image. Toutes les IA et applications de Machine Learning, sont sujettes au même problème. ChatGPT n’est d’ailleurs pas en reste sur la question.
Corrections ou nouveaux biais ?
Cependant les critiques à propos des biais de ChatGPT semblent plutôt aller dans l’autre sens. Ce sont essentiellement des conservateurs, Elon Musk en tête, qui le trouvent top ‘woke’ et coupable de biais en faveur de la gauche progressiste.
Si ces biais sont probablement largement exagérés et peuvent nous sembler plutôt légitimes, ils restent néanmoins réels. Ils sont en fait la conséquence d’une volonté de contrer les biais d'algorithme constatés avec les premières IA du genre.
En 2016 déjà, Microsoft avait par exemple lancé une IA conversationnelle sur Twitter nommée Tay. En moins de 24h, Tay a tenu des propos racistes et misogynes. Cette expérience malheureuse a évidemment amené les créateurs d’IA à vouloir mettre en place une solution pour contrer les biais qui peuvent l’amener à générer ce genre de textes.
Comme expliqué le mois dernier sur leur Blog, OpenAI a mis en place une procédure de Fine tuning, reposant sur une modération humaine (dont les fameux Kenyans à 2$/h).
Mais si elle est nécessaire, cette procédure peut, à son tour, entraîner ses propres biais. Même si il a été demandé aux examinateurs de rester politiquement neutre, cela n’aura pas nécessairement été le cas. Et puis, qu’est-ce que cela veut dire “politiquement neutre” ? Cette idée elle-même n’est elle pas une manière de décider une sorte de biais ? Peut-on seulement imaginer une réponse universelle à la question de ce qui serait acceptable ou non dans le discours d’une IA ? Et est-ce vraiment souhaitable ?
Il n’y a pas d’IA impartiale
Pourrait on finalement mettre au point une IA complètement impartiale ?
A ce stade, cela semble très peu probable. Tout simplement parce qu’un esprit humain entièrement impartial n’existe pas non plus.
Alors oui, si nous pouvions éliminer d’un ensemble de données tous les préjugés conscients et inconscients liés à la race, au genre et à d'autres notions idéologiques, nous serions en mesure de créer une IA qui prend des décisions impartiales basées sur des données.
Mais cela ne me semble pas réaliste. Les préjugés et les biais de pensée sont dans la nature humaine - penser le contraire est déjà en biais. Ce sont donc des humains biaisés qui génèrent les données et ce sont encore des humains, eux aussi biaisés, qui vérifient les données pour détecter et corriger les biais 🤪
Il ne faudrait pas pour autant adopter une posture fataliste et accepter tous les biais comme normaux - et encore moins comme souhaitables. Nous pouvons en effet lutter contre les biais de l'IA pour les limiter en testant les données et les algorithmes, en ayant recours aux meilleures pratiques pour recueillir et utiliser des données et créer des algorithmes d'IA.
Je pense aussi que nous pouvons (et devons) nous poser la question de ce que nous souhaitons comme IA et quels sont les biais que nous sommes prêts à accepter ou non, en tant qu’individus et en tant que société.

🛠️ App, outils et trucs cool
DeepAgency, le premier studio photo 100% IA, sans appareil photo ni mannequin (ce sont eux qui sont derrière Ailice, l’influenceuse IA dont je te parlais la semaine dernière)
Deux CRM viennent d’intégrer un assistant IA qui peut accomplir des tâches et répondre à des questions sur les clients ou les efforts de vente : Einstein GPT pour SalesForce et ChatSpot pour HubSpot
Sumplete est un nouveau jeu du genre Sudoku imaginé et codé par ChatGPT (explications détaillées)
Whimsical présente son IA pour créer des Mind Map.
Chat D-ID permet d’avoir une conversation en face à face avec Alice, un avatar de ChatGPT qui parle.
DuckDuckGo, le moteur de recherche qui met l'accent sur la protection de la vie privée, a annoncé l’arrivée de DuckAssist (basé sur ChatGPT ?).
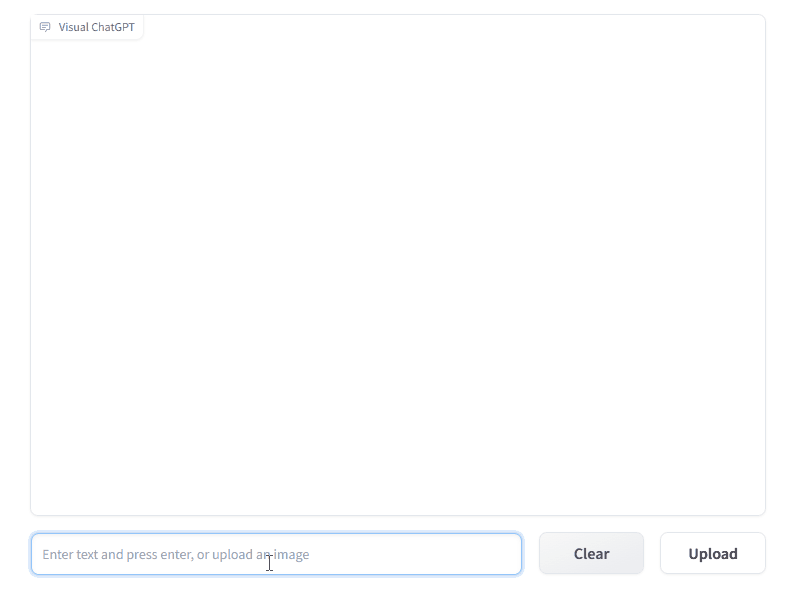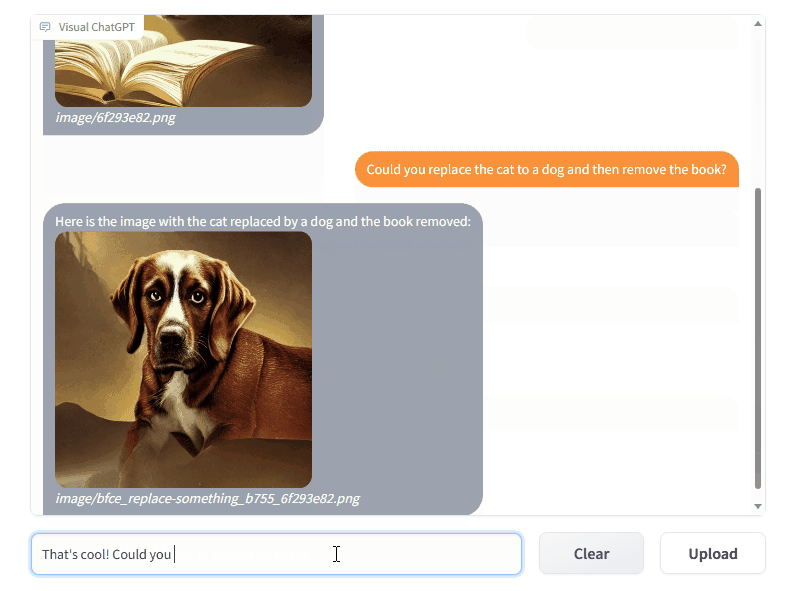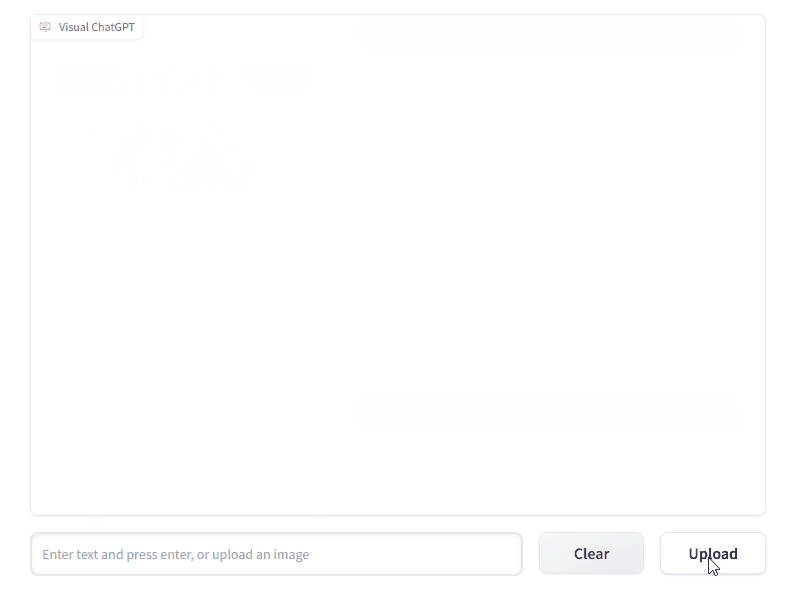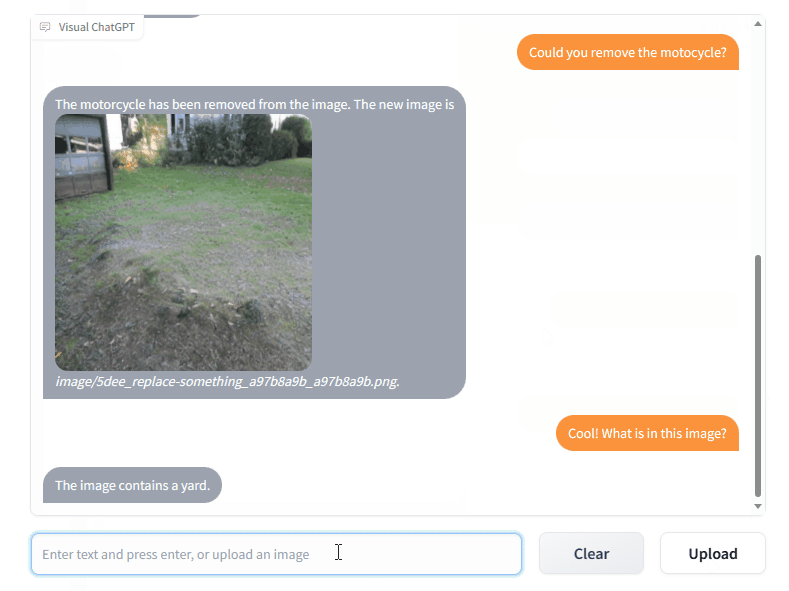
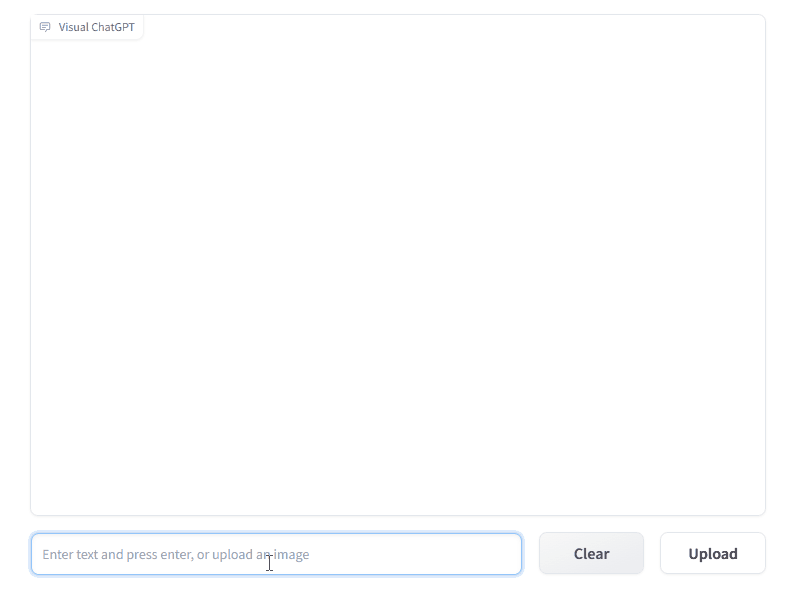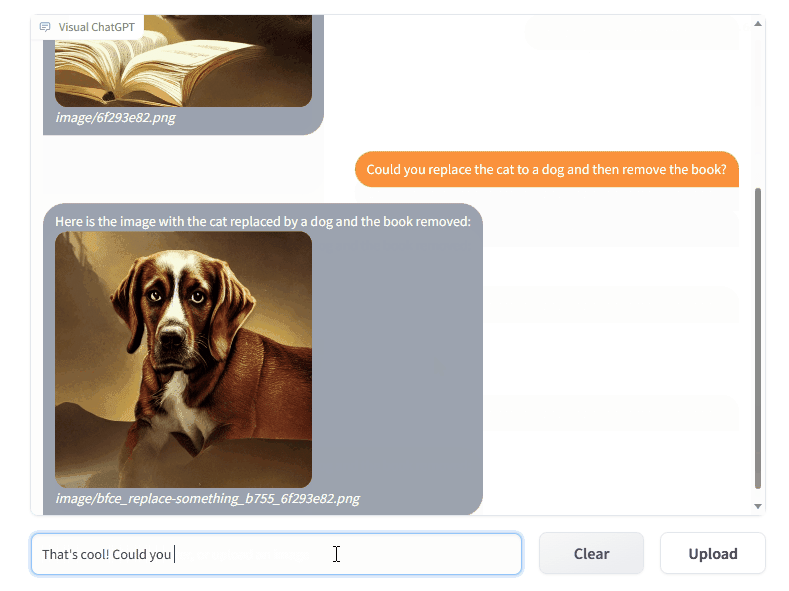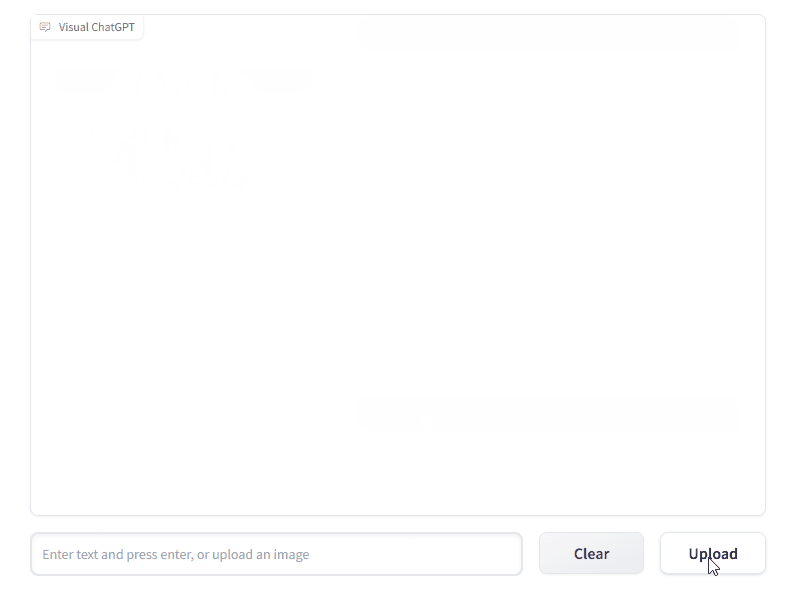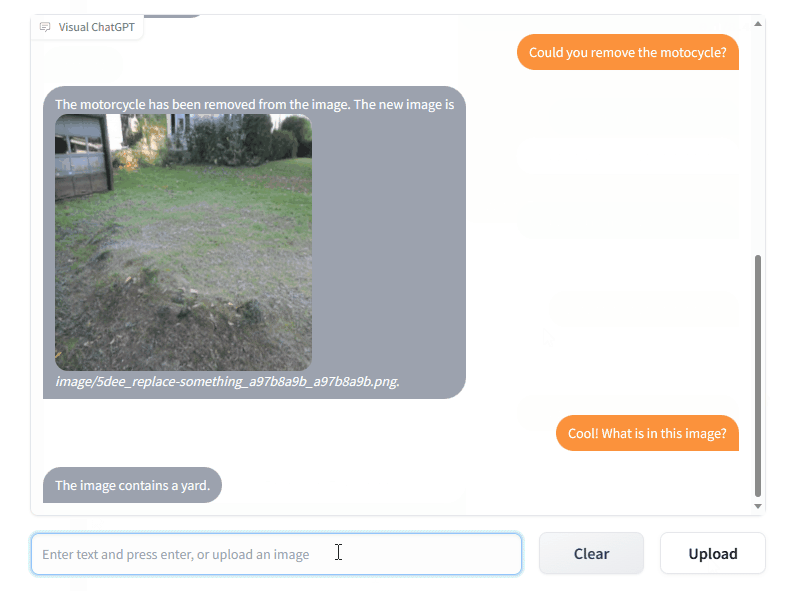
Microsoft a partagé le code de Visual ChatGPT, un outil qui combine ChatGPT et plusieurs modèles visuels pour intégrer des images à la discussion, avec la possibilité de les modifier :

📰 L’actu en (très) bref
Google redéfini ce que sera Bard
Jack Krawczyk, chef de produit de Bard, a clarifié que ce dernier n'est pas destiné à la recherche.
Bard ne sera donc pas juste une réponse à Bing AI (de Microsoft) mais plutôt un chatbot qui agira comme un compagnon créatif.
Le rôle de Bard sera d'être un appui pour l'utilisateur dans son travail personnel.
Ce repositionnement serait en grande partie lié aux critiques reçues après les premiers tests en interne par des employés de Google.
Toujours aucune date de sortie annoncée pour Bard.
Microsoft Azure inclut désormais ChatGPT 🇫🇷
ChatGPT rejoint d'autres modèles d'IA tels que Dall-E 2, GPT-3.5, Codex et d'autres grands modèles de langage déjà inclus dans Azure OpenAI Service.
L'ajout de ChatGPT ouvre de multiples possibilités pour les clients qui souhaitent intégrer l'IA dans leur entreprise.
Un accord européen sur la définition de l’IA 🇬🇧
Le Parlement européen a adopté la définition de l'AI Act utilisée par l'OCDE
Cette définition de l'IA repose sur ses capacités clés de perception, d'apprentissage et de décision, indépendamment de la technologie utilisée.
Le but est de pouvoir simplifier la régulation et la surveillance de l'IA en Europe.
Certains experts craignent cependant que cette définition ne soit pas suffisante pour couvrir toutes les formes d'IA et leurs évolutions rapides.
Google Traduction s’approche des 1000 langues 🇫🇷
Actuellement, Google Traduction n'est disponible que dans 130 langues.
Google travaille sur une IA nommée Modèle universel de la Parole et qui pourrait traduire ses services en 1000 langues différentes.
Ce modèle a été formé sur base de 12 millions d'heures de parole et 28 milliards de phrases écrites, couvrant plus de 300 langues.
Trouver des données pour les langues parlées par moins de vingt millions de personnes reste cependant très difficile.
Google est optimiste quant à l'adaptation de son modèle à de nouvelles langues et à de nouvelles données.
Nous voilà déjà arrivés à la fin de cette édition. J'espère que tu as trouvé autant de plaisir à la lire que moi à l'écrire.
Que ce soit le cas ou non, n’hésite pas à me répondre pour me donner tes impressions, partager une idée ou suggérer un sujet ou des liens pour une prochaine newsletter.
Thomas
PS : Si ce n’est pas déjà fait, n'oublie pas de t’abonner pour recevoir Brainy Sunday la semaine prochaine. Pense aussi à la partager autour de toi et sur tes réseaux.
